Web парсінг в Golang: Повна інструкція 2023
Web парсінг в Golang: Повна інструкція 2023
25 січня 2023 · 13 хв. читання https://www.zenrows.com/blog/web-scraping-golang#prerequisites
Веб парсінг в Golang є популярним підходом для автоматичного отримання даних з Інтернету. Виконайте цей покроковий посібник, щоб навчитися легко збирати дані в Go та познайомитися з популярними бібліотеками Colly та chromedp.
Давайте розпочнемо!
Передумови
Налаштуйте середовище
Ось передумови, які ви маєте виконати для цього підручника:

Go 1.19+: Підійде будь-яка версія Go, яка перевищує або дорівнює 1.19. Тут ви побачите версію 1.19 у дії, оскільки вона є останньою на момент написання.
IDE для Go: Visual Studio Code з Go extension є рекомендованим.
Перш ніж продовжити роботу з цим посібником із копіювання веб-сторінок, переконайтеся, що у вас встановлено необхідні інструменти. Перейдіть за наведеними вище посиланнями, щоб завантажити, інсталювати та налаштувати необхідні інструменти за допомогою майстрів встановлення.
Налаштуйте проект Go
Після встановлення Go настав час ініціалізувати ваш проект web парсера Golang.
Створіть папку web-scraper-go і перейдить до неї за допомогою команд у терміналі:
Потім запустіть наведену нижче команду:
Команда init ініціалізує модуль Go web-scraper у папці проекту web-scraper-go.
Каталог web-scraper-go тепер міститиме файл go.mod, який виглядає наступним чином:
Зауважте, що останній рядок змінюється залежно від вашої мовної версії.
Тепер ви готові налаштувати свій сценарій Go для збирання web сторінок. Створіть файл scraper.go та ініціалізуйте його, як показано нижче:
Перший рядок містить назву глобального пакета. Далі виконується імпорт, а потім функція main(). Це являє собою точку входу будь-якої програми Go та міститиме логіку веб-збирання Golang.
Запустіть сценарій, щоб переконатися, що все працює належним чином:
У ході нормального виконання сценарія, термінал повинен надрукувати наступне:
Тепер, коли ви налаштували базовий проект Go, давайте глибше заглибимося в те, як створити збір даних за допомогою Golang.
Як парсити веб-сайт з Go
Щоб дізнатися, як сканувати web сайт за допомогою Go, використовуйте ScrapeMe як цільовий веб-сайт.
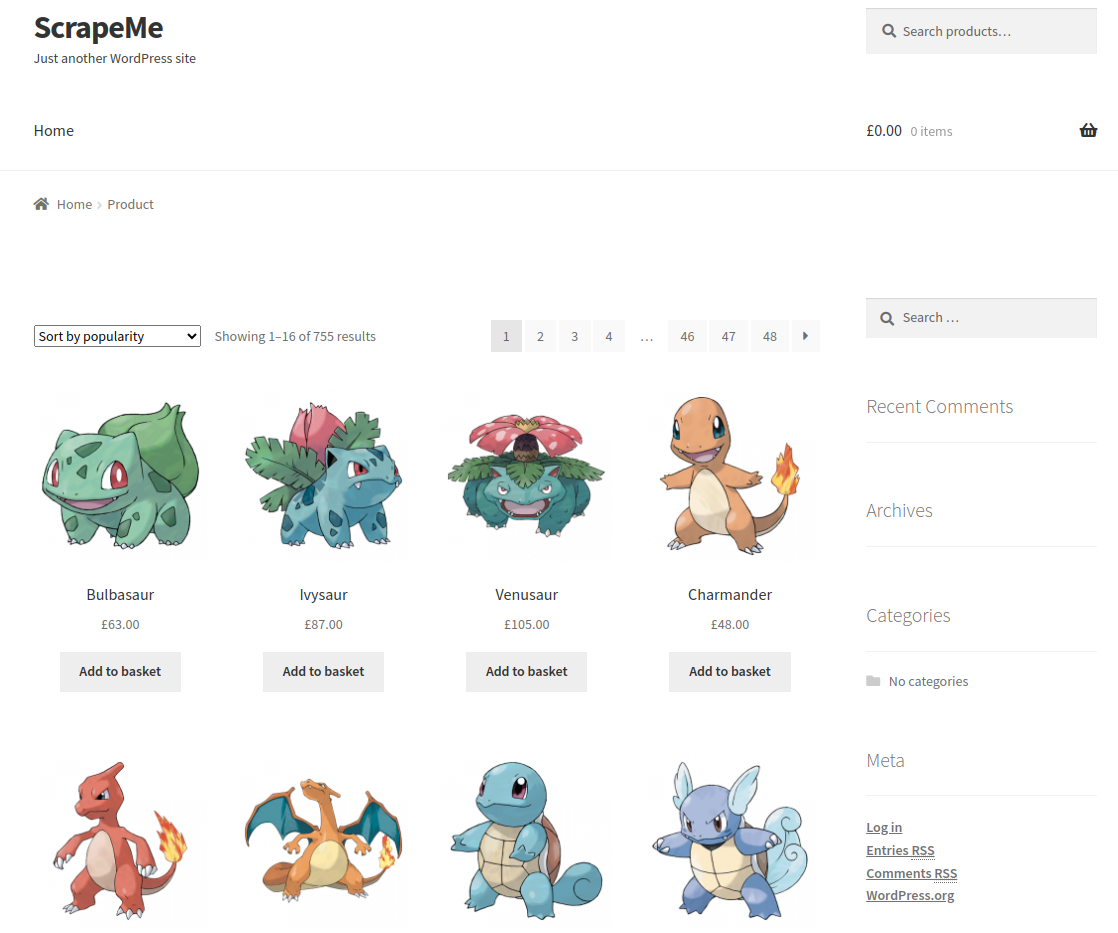
Як ви бачите вище, це магазин Pokémon. Наша місія полягатиме в тому, щоб отримати з нього всі дані про продукт.
Крок 1: Початок роботи з Colly
Colly — це бібліотека з відкритим вихідним кодом, яка забезпечує простий інтерфейс на основі зворотних викликів для написання парсера, сканера або павука. Вона постачається з розширеним API парсера Go, який дозволяє завантажувати HTML-сторінку, автоматично аналізувати її вміст, вибирати HTML-елементи з DOM і отримувати з них дані.
Встановіть Colly та його залежності:
Ця команда створить файл go.sum у корені вашого проекту та оновить файл go.mod з усіма необхідними залежностями відповідно.
Дочекайтеся завершення процесу встановлення. Потім імпортуйте Colly у свій файл scraper.go, як показано нижче:
Перш ніж розпочинати роботу з цією бібліотекою, вам потрібно зрозуміти кілька ключових понять.
По-перше, головною сутністю Colly є Collector. Collector дозволяє виконувати HTTP-запити. Крім того, це надає вам доступ до зворотних викликів web парсінга, які пропонує інтерфейс Colly.
Ініціалізуйте Colly Collector за допомогою функції NewCollector:
Використовуйте Colly, щоб відвідати веб-сторінку за допомогою Visit():
Приєднайте різні типи функцій зворотного виклику до Collector, як показано нижче:
Ці функції виконуються в такому порядку:
OnRequest(): Викликається перед виконанням HTTP-запиту за допомогою Visit().
OnError(): Викликається, якщо сталася помилка під час запиту HTTP.
OnResponse(): Викликається після отримання відповіді від сервера.
OnHTML(): Викликається відразу після OnResponse(), якщо отриманий вміст є HTML.
OnScraped(): Викликається після всіх виконань зворотного виклику OnHTML().
Кожна з цих функцій приймає зворотний виклик як параметр. Спеціальний зворотний виклик виконується, коли виникає подія, пов’язана з функцією Colly. Таким чином, ці п’ять функцій Colly допоможуть вам створити ваш збірник даних Golang.
Крок 2. Відвідайте сторінку Target HTML
Виконайте запит HTTP GET, щоб завантажити цільову HTML-сторінку в Colly за допомогою:
Функція Visit() запускає життєвий цикл Colly, запускаючи подію onRequest. Далі будуть інші події.
Крок 3. Знайдіть цікаві елементи HTML
У цьому підручнику Go зі збирання даних йдеться про отримання всіх даних про продукт, тому давайте візьмемо елементи продукту HTML. Клацніть правою кнопкою миші елемент продукту на сторінці, а потім виберіть опцію «Inspect», щоб отримати доступ до розділу DevTools:
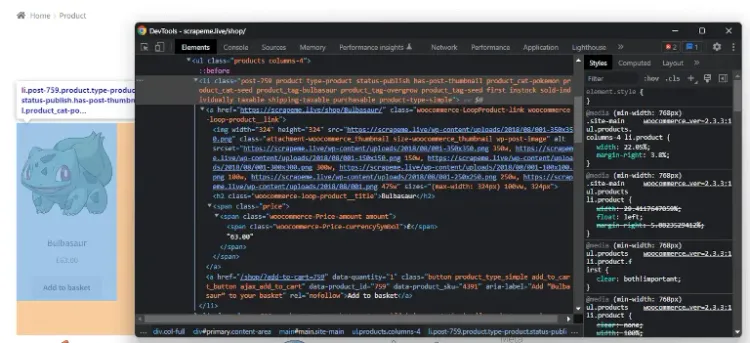
Зверніть увагу, що HTML-елемент target li має клас .product і зберігає:
Елемент із URL-адресою продукту.
Елемент img із зображенням продукту.
Елемент h2 із назвою продукту.
Елемент .price із ціною продукту.
Виберіть усі елементи продукту li.product HTML на сторінці за допомогою Colly:
Функцію OnHTML() можна пов’язати з селектором CSS і функцією зворотного виклику. Colly виконає зворотний виклик, коли знайде елементи HTML, що відповідають селектором. Зверніть увагу, що параметр e функції зворотного виклику представляє один HTMLElement li.product.
Давайте тепер подивимося, як отримати дані з елемента HTML за допомогою функцій, наданих Colly.
Крок 4: Вилучіть дані продукту з вибраних елементів HTML
Перш ніж розпочати, вам потрібна структура даних, у якій зберігатимуться зібрані дані. Визначте структуру PokemonProduct таким чином:
Якщо ви не знайомі з цим, Go Struct — це набір введених полів, які можна використовувати для збору даних.
Потім ініціалізуйте slice PokemonProduct, який міститиме зібрані дані:
У Go зрізи забезпечують ефективний спосіб роботи з послідовностями введених даних. Ви можете думати про них як про списки.
Тепер реалізуйте логіку скрапінгу:
Інтерфейс HTMLElement надає методи ChildAttr() і ChildText(). Вони дозволяють витягувати текст значення атрибута з дочірнього елемента, визначеного селектором CSS відповідно. За допомогою двох простих функцій ви реалізували всю логіку вилучення даних.
Нарешті, ви можете додати новий елемент до фрагмента зібраних елементів за допомогою append(). Дізнайтеся більше про те, як append() працює в Go.
Фантастично! Ви щойно навчилися очищати веб-сторінку в Go за допомогою Colly.
Export the retrieved data to CSV as a next step.
Крок 5. Перетворіть зібрані дані у CSV
Експортувати зібрані дані у файл CSV у Go за такою логікою:
Цей фрагмент створює файл products.csv і ініціалізує його стовпцями заголовків. Потім він виконує ітерацію по фрагменту зібраних PokemonProducts, перетворює кожен із них на новий запис CSV і додає його до файлу CSV.
Щоб цей фрагмент працював, переконайтеся, що у вас є такі імпорти:
Отже, ось так зараз виглядає остаточний код програми прарсінгу:
Запустіть ваш код Go за допомогою:
Потім ви знайдете файл products.csv у кореневому каталозі вашого проекту. Відкрийте його, і він повинен містити це:
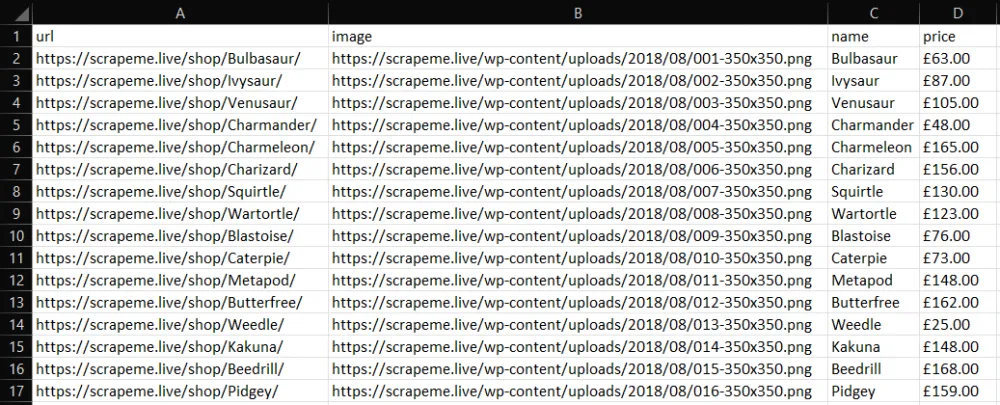
Це воно!
Передові методи веб-збирання за допомогою Golang
Тепер, коли ви знаєте основи web парсінгу за допомогою Go, настав час заглибитися в більш просунуті підходи.
Web Crawling with Go
Зверніть увагу, що список продуктів Pokémon, які потрібно отримати, розбитий на сторінки. У результаті цільовий веб-сайт складається з багатьох веб-сторінок. Якщо ви хочете отримати всі дані про продукт, вам потрібно відвідати весь веб-сайт.
Щоб сканувати веб-сторінку в Go та сканувати весь веб-сайт, вам спочатку знадобляться всі посилання на сторінки. Отже, клацніть правою кнопкою миші на будь-якому елементі HTML з номером сторінки та виберіть опцію «Inspect».
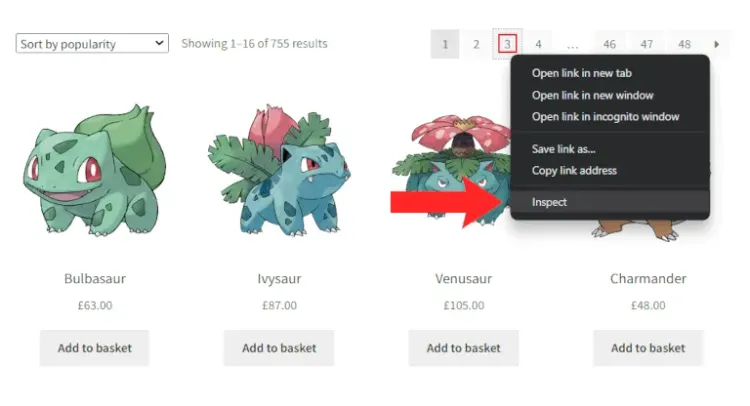
Ваш браузер надасть доступ до розділу DevTools нижче з виділеним вибраним елементом HTML:
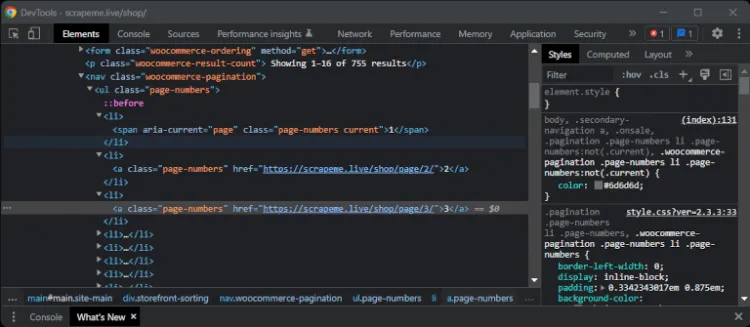
Якщо ви подивитесь на всі HTML-елементи розбиття на сторінки, то побачите, що всі вони ідентифіковані селектором CSS .page-numbers. Використовуйте цю інформацію, щоб застосувати сканування в Go, як показано нижче:
Оскільки ви, можливо, захочете програмно зупинити роботу зберігача даних Go, вам знадобиться обмежувальна змінна. Це максимальна кількість сторінок, які може відвідати веб-павук Golang.
В останньому рядку фрагмент сканує першу сторінку розбивки. Потім запускається подія onHTML. У зворотному виклику onHTML() веб-сканер Go шукає нові посилання на сторінки. Якщо він знаходить нове посилання, він додає його до черги сканування. Потім він повторює цю логіку з новим посиланням. Зрештою, він зупиняється, коли досягається ліміт або немає нових сторінок для сканування.
Наведена вище логіка сканування була б неможливою без змінних фрагментів pagesDiscovered і pagesToScrape. Вони допомагають відстежувати, які сторінки сканер Go зібрав і незабаром відвідає.
Зауважте, що функція contains() є спеціальною функцією утиліти Go, визначеною нижче:
Його мета — просто перевірити, чи присутній рядок у фрагменті.
Молодець! Тепер ви можете сканувати веб-сайт із сторінками ScrapeMe за допомогою Golang!
Уникайте блокування
На багатьох веб-сайтах реалізовано анти-скрапінг-анти-бот-техніку. Найпростіший підхід передбачає заборону HTTP-запитів на основі їх заголовків. Зокрема, вони зазвичай блокують HTTP-запити, які надходять із недійсним заголовком User-Agent.
Установіть глобальний заголовок User-Agent для всіх запитів, які виконує Colly, за допомогою поля UserAgent Collect таким чином:
Не забувайте, що це лише одна з багатьох технік проти парсінгу, з якими вам, можливо, доведеться мати справу.
Використовуйте ZenRows, щоб легко подолати ці проблеми під час сканування веб-сторінок.
Паралельний Web парсінг в Golang
Парсінг даних у Go може зайняти багато часу. Причиною може бути повільне підключення до Інтернету, перевантажений веб-сервер або просто велика кількість сторінок, які потрібно отримати. Ось чому Colly підтримує паралельне сканування! Якщо ви не знаєте, що це означає, паралельне сканування веб-сторінок у Go включає вилучення даних із кількох сторінок одночасно.
Докладніше, це список усіх сторінок розбиття на сторінки, які має відвідати ваш сканер:
Завдяки паралельному скануванню ваш павук для збирання даних Go зможе відвідувати та отримувати дані з кількох веб-сторінок одночасно. Це значно пришвидшить процес вишкрібання!
Використовуйте Colly для реалізації паралельного веб-павука:
Colly поставляється з асинхронним режимом. Якщо ця можливість ввімкнена, це дозволяє Colly відвідувати кілька сторінок одночасно. Зокрема, Colly відвідає стільки сторінок одночасно, скільки значення параметра Parallelism.
Увімкнувши паралельний режим у вашому сценарії web парсінга Golang, ви досягнете кращої продуктивності. У той же час вам може знадобитися змінити частину логіки коду. Це тому, що більшість структур даних у Go не є потокобезпечними, тому ваш сценарій може зіткнутися з умовою змагання (race condition).
Чудово! Ви щойно навчилися основам паралельного сканування веб-сторінок!
Парсінг Web сайтів із динамічним вмістом за допомогою Headless браузера в Go
Веб-сайт зі статичним вмістом постачається з усім вмістом, попередньо завантаженим на HTML-сторінки, які повертає сервер. Це означає, що ви можете отримати дані з веб-сайту зі статичним вмістом, просто розібравши його вміст HTML.
З іншого боку, інші веб-сайти покладаються на JavaScript для візуалізації сторінок або використовують його для виконання викликів API та асинхронного отримання даних. Такі веб-сайти називаються веб-сайтами з динамічним вмістом, і для їх відтворення потрібен браузер.
Вам знадобиться інструмент, який може запускати JavaScript, наприклад безголовий браузер, бібліотека якого надає можливості браузера та дозволяє завантажувати веб-сторінку в спеціальному браузері без графічного інтерфейсу. Потім ви можете наказати безголовому браузеру імітувати взаємодію користувача.
The most popular headless browser library for Golang is chromedp. Install it with:
Найпопулярнішою бібліотекою безголового браузера для Golang є chromedp. Встановіть його за допомогою:
Потім скористайтеся chromedp, щоб отримати дані зі ScrapeMe у браузері, як описано нижче:
Функція chromedp Nodes() дає змогу вказувати безголовому браузеру виконати запит. Таким чином ви можете вибрати елементи HTML продукту та зберегти їх у змінній nodes. Потім переберіть їх і застосуйте методи AttributeValue() і Text(), щоб отримати дані, які вас цікавлять.
Виконання веб-збирання в Go with Colly або chomedp нічим не відрізняється. Різниця між цими двома підходами полягає в тому, що chromedp виконує інструкції зі збирання в браузері.
With chromedp, you can crawl dynamic-content websites and interact with a web page in a browser as a real user would. This also means that your script is less likely to be detected as a bot, so chromedp makes it easy to scrape a web page without getting blocked.
За допомогою chromedp ви можете сканувати веб-сайти з динамічним вмістом і взаємодіяти з веб-сторінкою у браузері, як це робив би справжній користувач. Це також означає, що ваш сценарій з меншою ймовірністю буде виявлено як бот, тому chromedp дозволяє легко сканувати веб-сторінку без блокування.
Навпаки, Colly обмежений веб-сайтами зі статичним вмістом і не пропонує можливостей браузера.
Зібрати все разом: остаточний код
Ось так виглядає повний парсер Golang на основі Colly з скануванням і базовою логікою антиблокування:
Фантастично! Приблизно за 100 рядків коду ви створили веб-скребок у Golang!
Інші Web бібліотеки копіювання для Go
Інші чудові бібліотеки для веб-збирання за допомогою Golang:
ZenRows: Повний API для сканування веб-сторінок, який протидіє всім анти-ботовим заходам. Він оснащений можливостями безголового браузера, обходом CAPTCHA, ротаційними проксі-серверами тощо.
GoQuery: Бібліотека Go, яка пропонує синтаксис і набір функцій, подібних до jQuery. Ви можете використовувати його для виконання веб парсінгу так само, як це робили зроблено у JQuery.
Ferret: Переносна, розширювана та швидка система сканування веб-сторінок, спрямована на спрощення вилучення даних з Інтернету. Ferret дозволяє користувачам зосередитися на даних і базується на унікальній декларативній мові.
Selenium: Ймовірно, найвідоміший безголовий браузер, ідеальний для сканування динамічного вмісту. Він не пропонує офіційної підтримки, але є порт для його використання в Go.
Висновок
У цьому покроковому підручнику Go ви побачили будівельні блоки, щоб розпочати роботу з веб парсінгу за допомогою Golang.
Як підсумок, ви дізналися:
Як виконувати базові дії, що збирають дані за допомогою Colly.
Як досягти логіки сканування, щоб відвідати весь веб-сайт.
Причина, чому вам може знадобитися безголовий браузер Go.
Як скопіювати веб-сайт із динамічним вмістом за допомогою chromedp.
Парсінг може стати складним завданням через заходи проти парсінга, які застосовуються на кількох веб-сайтах. Багато бібліотек намагаються подолати ці перешкоди. Щоб уникнути цих проблем, найкраще використовувати API для копіювання веб-сайтів, наприклад ZenRows. Це рішення дозволяє обійти всі системи захисту від ботів одним викликом API.
Часті запитання
Як ви парсите в Golang?
Ви можете виконувати веб парсінг у Golang так само, як і в будь-якій іншій мові програмування. По-перше, отримайте бібліотеку Go для веб парсінга. Потім застосуйте його, щоб відвідати цільовий веб-сайт, вибрати елементи HTML, які вас цікавлять, і отримати з них дані.
Який найкращий спосіб парсінга за допомогою Golang?
Існує кілька способів сканування веб-сторінок за допомогою мови програмування Go. Як правило, це передбачає використання популярних бібліотек Go для веб-збирання. Найкращий спосіб очищення веб-сторінок за допомогою Golang залежить від конкретних вимог вашого проекту. Кожна з бібліотек має свої сильні та слабкі сторони, тому виберіть ту, яка найкраще підходить для вашого випадку використання.